前回の記事では、簡単な用語の説明などをしていました。
では、実際にOctoparseを使って、サイト内の情報を取得してみましょう。
1.Octoparseの入手
Octoparse自体は無料のwebスクレイピングツールです。
↑の公式サイトからダウンロード・インストール。公式サイトに手順が載っています。
ユーザー登録が必要なので、前後して公式サイトからユーザー登録をしてください。
2.Octoparseの設定
ログインが終わればこの画面に変わります。

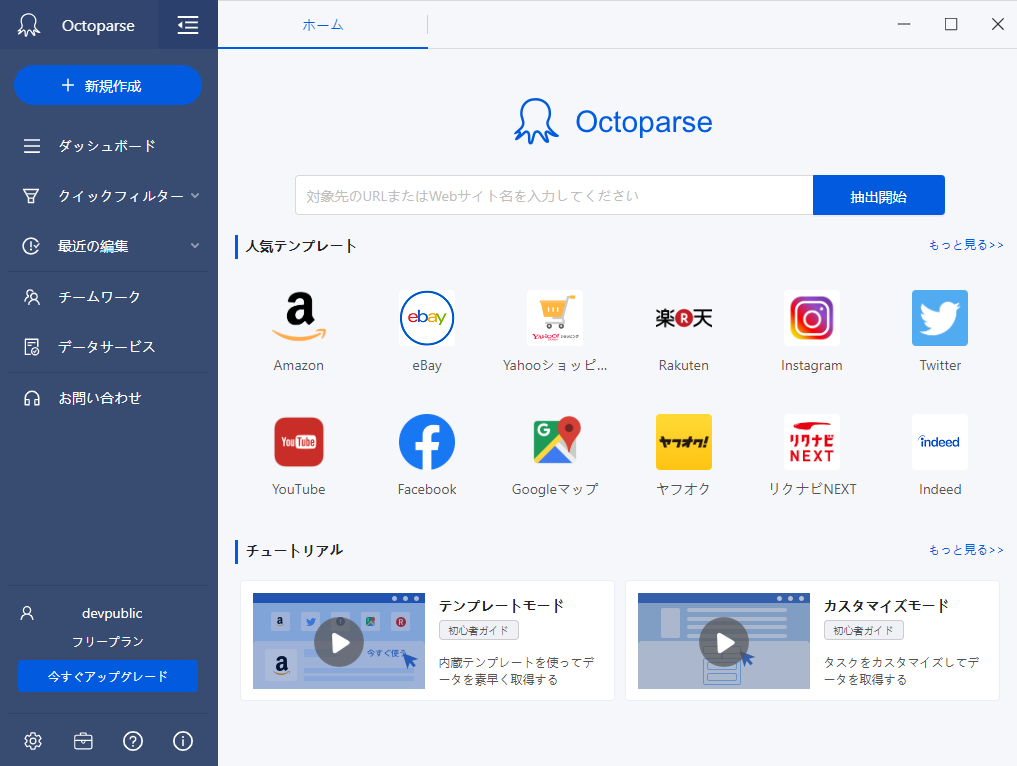
2.いざ、webスクレイピング
まずは調べたいサイトのURLを入力し、「抽出開始」をクリックしてください。
例として、このパブリックのブログURLで抽出してみます。
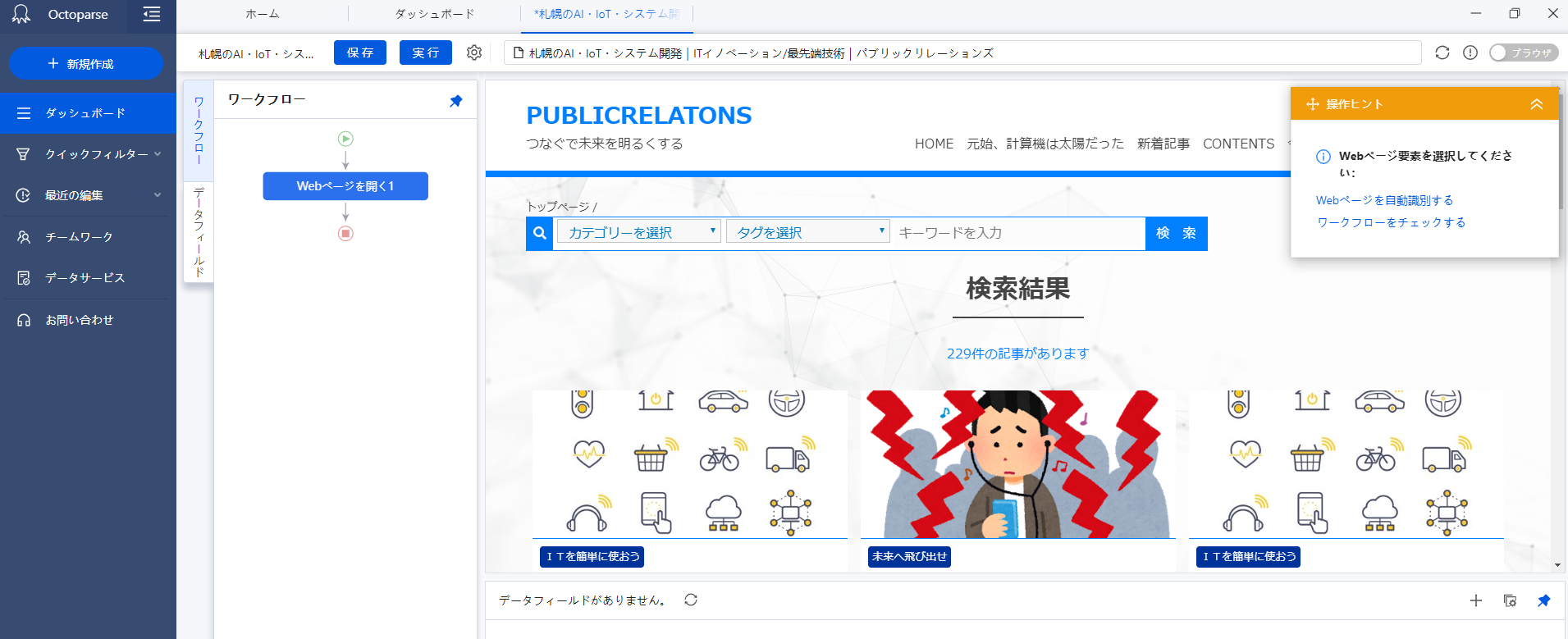
サイトが表示されました。
ここで、「webページを自動識別する」をクリックすると
これだけで画面上の文章や各ブログ記事のURLを取得します。
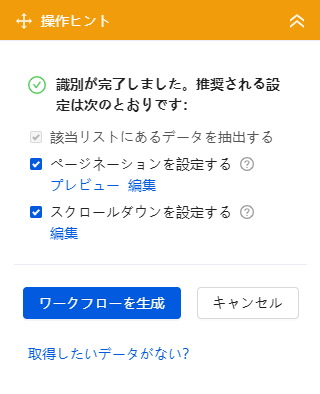
すると、上のようなダイアログが出てきます。
今回はトップの記事一覧のみ取得するためページ切り替えをするかどうかの
「ページネーションを設定する」のチェックを外します。
そして「ワークフローを生成」をクリックしてください。
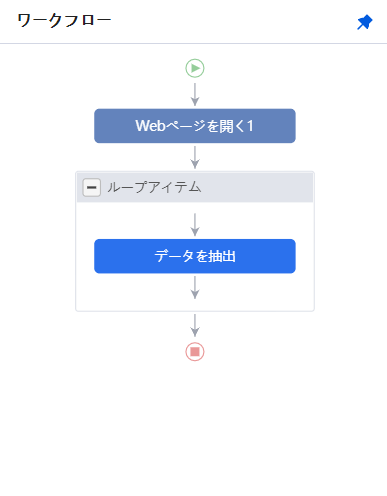
左にあったワークフローがこのように変化します
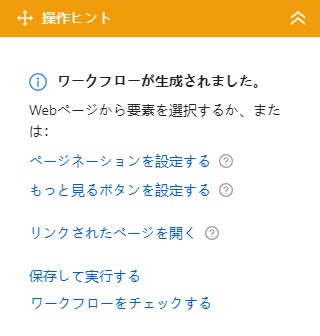
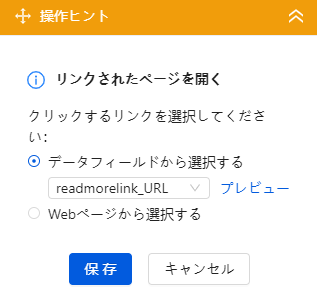
「リンクされたページを開く」をクリックすると、先ほど取得したブログ記事のURLに設定し保存します。
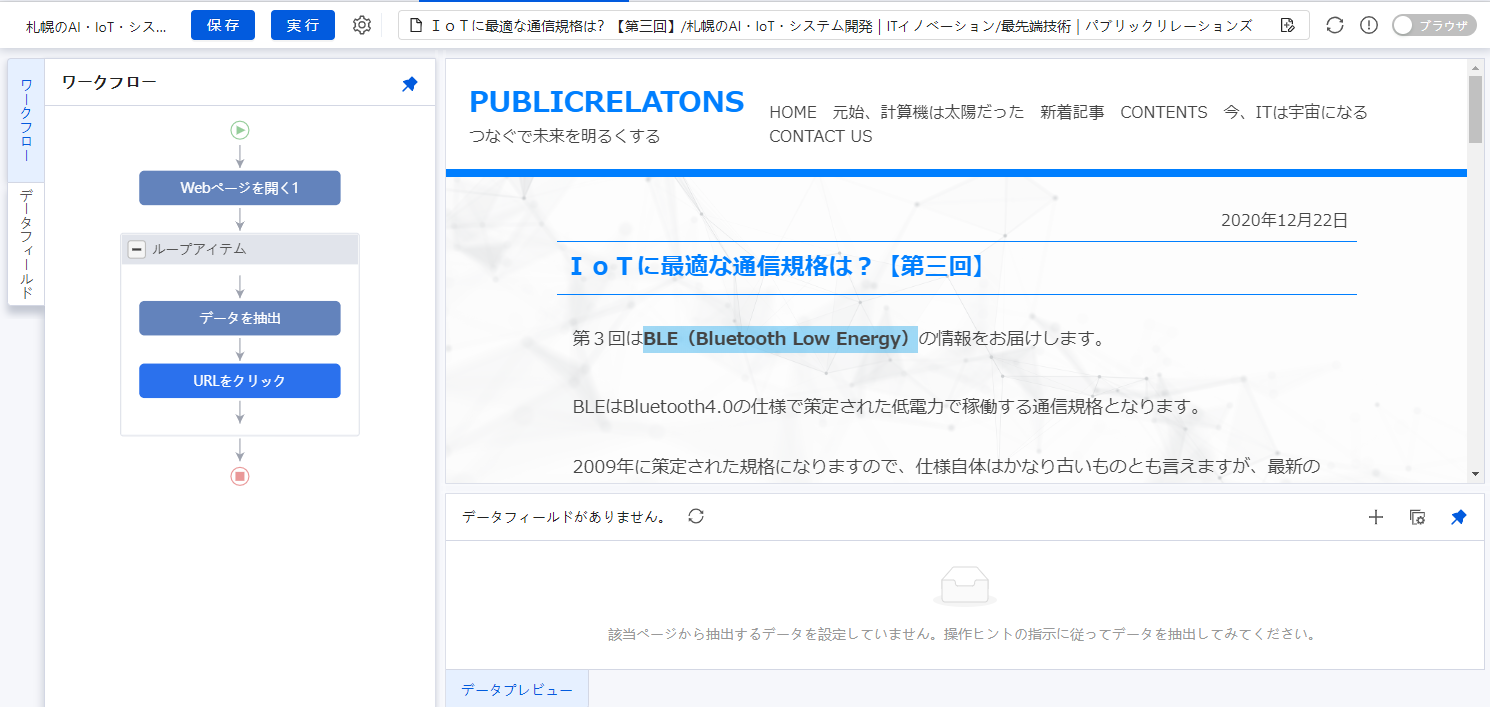
URLがよみこまれブログ記事が表示されます。
記事をクリックするし、「選択した要素のテキストを抽出する」をクリックします。
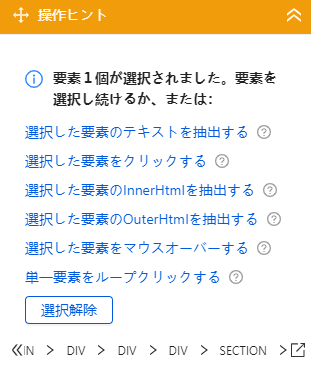
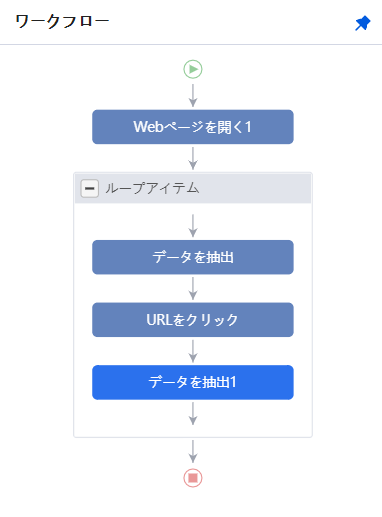
ワークフローはおそらくこのような形になっているはずです。
まず、webページを開きブログ一覧から、記事情報を抽出し、記事のURLをクリックします。
そして開いたブログ記事の内容を取得する。
この一連の作業を今設定した手順で、一覧ページから記事内容を取得することが出来ます。
3.次回
次回は、ファイルに抽出した内容の見方をご紹介します。
お問い合わせ - お気軽にお問い合わせください -

株式会社 パブリックリレーションズ 〒064-0807 北海道札幌市中央区南7条西1丁目13番地 弘安ビル5階 011-520-1800 011-520-1802
メールでのお問い合わせはこちら