社内AI案件で学習データとして使う画像が必要になりました。
1枚ずつ手作業で集めるのはいろいろ調べていたところ、Pythonライブラリにクロールフレームワークの「icrawler」なるものがあったので使ってみることにしました。
1.icrawlerパッケージのインストール
PyPIパッケージとして配布されているので簡単にインストールが可能です。
コマンドプロンプトから次のコマンドを実行します。
pip install icrawler
2.icrawlerライブラリの使い方
icrawlerライブラリにあるBing検索用のBingImageCrawlerクラスを使ってクロールプログラム(weed.py)を作ります。
weed.py
# クローラBing用のクラスをインポート
from icrawler.builtin import BingImageCrawler
# クローラの生成
crawler = BingImageCrawler(
downloader_threads=10, # スレッド数
storage={'root_dir': 'weed'}) # ダウンロード先のフォルダ名
# クロールの実行
crawler.crawl(
keyword="雑草", # 検索キーワード
max_num=1000) # ダウンロードする画像数の最大
コマンドプロンプトから実行(ダブルクリックも可)するとクロールが開始されます。
プログラムのstorageで指定したフォルダが作成されダウンロードしたファイルが格納されます。
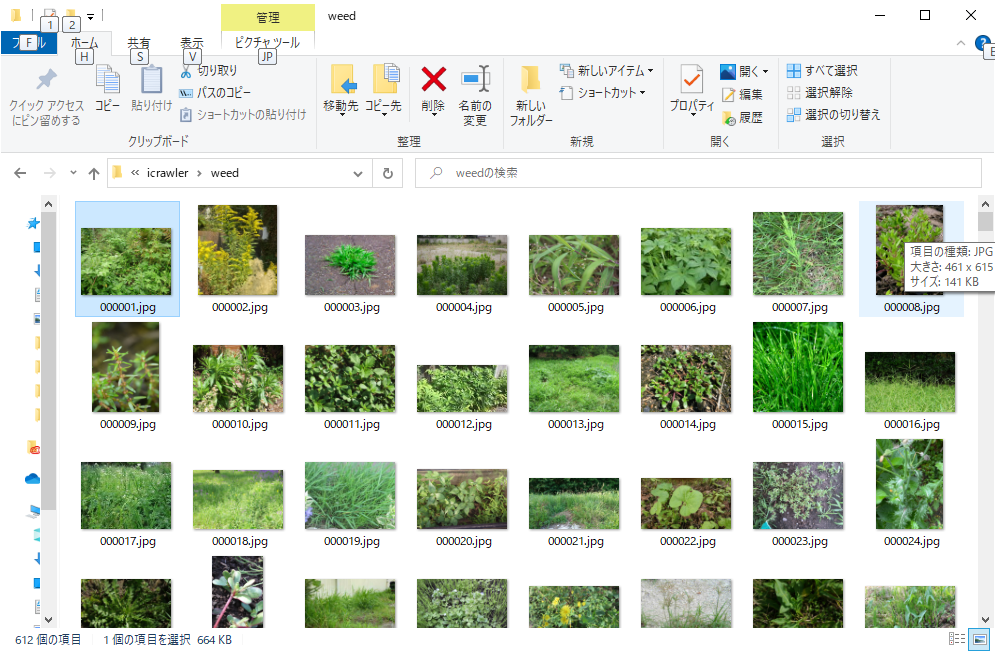
簡単に雑草ファイルの収集をすることができました。 全部で612ファイルがダウンロードされていて、ファイルの分別をする必要はありますが収集してもらえるだけで後続の作業がずいぶん楽になります。
お問い合わせ - お気軽にお問い合わせください -

株式会社 パブリックリレーションズ 〒064-0807 北海道札幌市中央区南7条西1丁目13番地 弘安ビル5階 011-520-1800 011-520-1802
メールでのお問い合わせはこちら